
Sound and Vision Archive
This is the current audiovisual collection of The Netherlands Institute for Sound and Vision (NISV), one of the most important Dutch audiovisual archives, which collects, looks after, and provides access to over 70% of the Dutch audio-visual heritage. This version of the collection uses data from DAAN, the new media management system for NISV, which went into use in July 2018. The metadata model of DAAN is different to that of the previous media management system, so you will notice differences in the metadata compared to the old Audiovisual Collection. In principle, the same metadata is available, but the names of the fields and their structure have changed. See the bottom of this page for more information.
The following figures give answers to common questions about the composition of this collection:
What part of the collection is included in the Media Suite?
Via the Media Suite, The Netherlands Institute for Sound and Vision offers access to its entire audiovisual collection.
What years does the archive cover?
The NISV audiovisual collection includes items from 1877 to the present day.
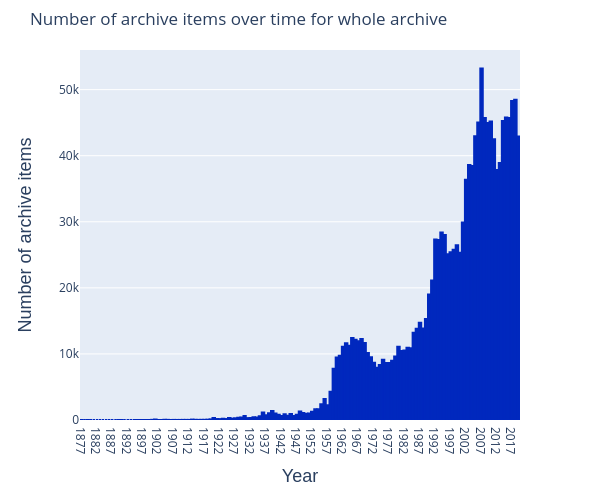
Figure 1: Number of programs in the archive over time
How often is the data updated in the Media Suite?
This collection is updated daily.
What kind of media is included?
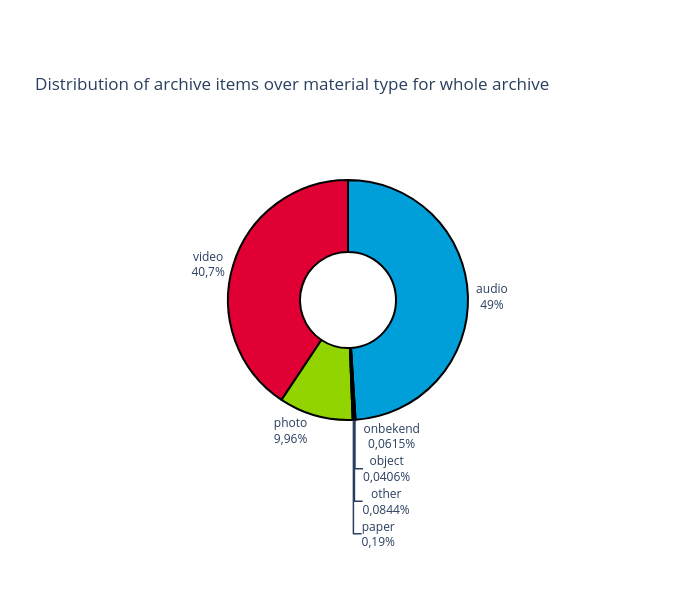
Figure 3: Distribution of items over material type
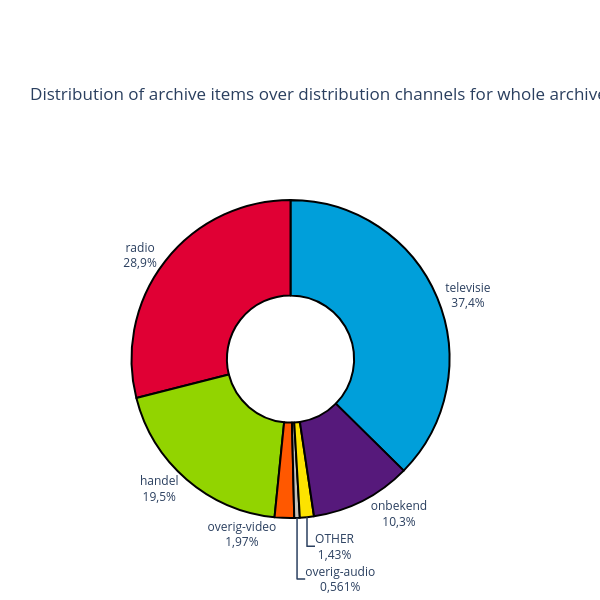
Figure 4: Distribution of programmes over media
What portion of the collection is digital?
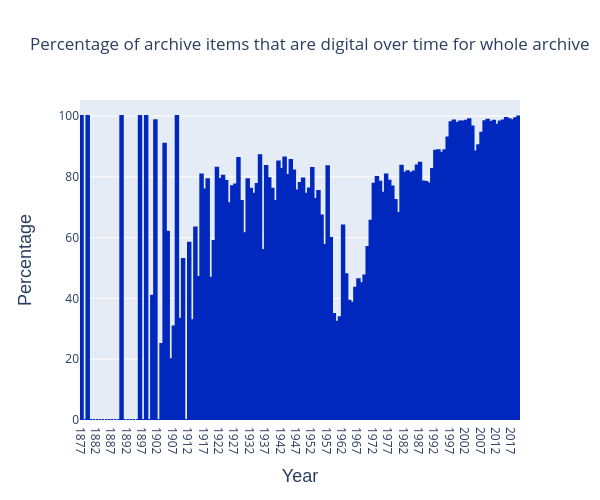
Figure 5: Percentage of material that is digital over time
Does the collection include enrichments?
Progressively, the NISV audiovisual collection is being enriched with automatic speech recognition (ASR) transcripts.
More recent items in the NISV collection contain face recognition, speaker recognition and extracted thesaurus labels. These will be made available in the Media Suite in due course.
Autocomplete options
This collection currently offers autocomplete options from the Persons in the GTAA, the thesaurus used by Sound and Vision. When search text is typed into the Search field, a list of persons matching the text appears. Note: the autocomplete offers ALL matching Persons, independent of the search cluster selected. So a person can appear in the list when the ‘Persons - guest’ cluster is selected who has not appeared as a guest.
When a person is selected, the collection is searched for exact matches for any of the labels for that person in the GTAA. The GTAA contains persons who frequently appear in the Sound and Vision archive. As such the persons are predominantly from the Netherlands, but there are still many international persons included. Usually Dutch spellings are used, for example Beethoven is entered as ‘Ludwig van Beethoven’. Alternative spellings are offered in some cases, for example ‘Ludwig von Beethoven’. Labels are available for both the name in its usual form, e.g. Ludwig van Beethoven, and for the inverted form of the name, ‘Beethoven, Ludwig van’. Partial matches are not found, so programmes containing only the surname ‘Beethoven’ will not be found.
The GTAA person terms are used for manually filling in person-related metadata fields in the collection, such as ‘guest’ and ‘actor’. These fields have a high accuracy and always match the preferred label of the GTAA term exactly. When searching in these fields the search results will be complete where the field has been filled in. Note that person-related metadata fields are only filled in for part of the Sound and Vision archive, and that the completeness of these fields varies greatly over time, in particular, recent material rarely contains these fields. Use the Inspect tool to find out more. Limit your search to the person-related metadata fields when precision is more important than recall.
Free-text fields, such as descriptions, do not use the GTAA terms. The names mentioned may match the labels in the GTAA, but also variations of the name may be used that do not exactly match any of the GTAA labels, or that match to a label for a different person. When searching in these fields results may therefore not be complete and could potentially even relate to a different person. However these fields are filled in for a much larger proportion of the collection, so potentially more search results may be found.
Many of the GTAA person names are linked to Wikidata. However, the labels from Wikidata are NOT used when searching, as these labels are often not specific enough. e.g. a surname or nickname.
Tip: To see which GTAA labels exist for a person, open the Additional Information page for that person. Click the GTAA link to view the person in the thesaurus.
Links to external data
A large number of persons in the GTAA, the thesaurus used by Sound and Vision, have been linked with the corresponding pages about those persons on Wikidata. These links were automatically generated by software, and then confirmed by crowdsourcing via the Mix'n'match facility offered by Wikidata. The link with the GTAA can be seen on the Wikidata page for the person, under the heading ‘GTAA ID’.
When you open the Additional Information page page for a person, then you will see the link to Wikidata if it exists.
Specialised collection metadata
The Metadata tab in the Resource Viewer has the following specialised metadata: Broadcaster - the organisation that broadcast the resource Genre - the genre(s) allocated to that resource by Sound and Vision ExternalSourceInfo - a link to view the resource in the Sound and Vision DAAN tool(a separate login is required for DAAN) Persons - persons that have been manually filled in in the specialised metadata fields for persons, e.g. actor, guest. Persons mentioned in textual descriptions or recognised in the subtitles/video/audio by software are NOT yet listed here. The manual person metadata fields are not filled in for all resources, so sometimes a message appears that there is no person information available. Click on a person to view links to additional information about that person, or to search for them in the Media Suite.
Where to find more information?
- For more background information about the NISV collection, visit the NISV collection page. See also the pages of the: NISV radio collection, and NISV television collection.
- For more information about the composition of this collection, and live updates about the ASR processing, visit the Collection statistics site maintained by NISV. -More information about the ASR enrichments can be found in the Media Suite documentation.
- For more information about the metadata of this collection, and the availability of the automatic enrichments use the Media Suite’s Inspect tool.
How to search in this collection?
To search the content of this collection, use the Media Suite’s Search tools.
Differences between the metadata fields of DAAN and iMMix
The DAAN system for storing archive metadata about Sound and Vision archive items uses a different data model to the previous system, iMMix. The existing iMMix data has been migrated to the DAAN model, and the content of all important fields has been preserved. The way some information is modelled has changed, some administrative fields have been removed, and some important areas, such as IPR, have been extended to have more metadata fields.
Metadata fields with the same meaning in both iMMix and DAAN have been given the same labels in the Media Suite, so you should notice no difference for the bulk of the metadata. Where the structure of fields has changed, you will see a change in the names of the metadata fields. The biggest difference in existing fields is that ‘segment’ fields, those relating to clips within a program, now start with ‘logTrackItems.ltScenedesc’. DAAN also has many new fields with enrichment information, such as face recognition, extracted labels etc. These appear with the prefix ‘logTrackItems’ at present. In due course, as these are further integrated into the Media Suite, they will be given more user-friendly labels. The next section describes the main differences you will see when using the Media Suite
Differences when using the Media SuiteResource Viewer
The viewer shows the same information for DAAN programs as for iMMix. The same labels have been used, so you should not notice a difference in the headings. The date format has changed, so you will now see dates in the format ‘year-month-day’ instead of ‘day-month- year’. E.g. an item from 10th November 1997 will have the date ‘1997-11-10’. When clicking on the ‘full metadata’ button, you will see the metadata from the DAAN model, so this will appear very differently. To understand this metadata, see the ‘Advanced information’ section below.
Finding specific resources
You may have links or bookmarks to resources from the old Sound and Vision (iMMix) collection. These will not work for the new Sound and Vision (DAAN) collection. To find a specific resource from iMMix in the DAAN collection, first look it up in the old Sound and Vision collection and note the ResourceId, which has the format ‘12345@program’. The DAAN resource has a very similar ID; to construct it take the numbers before the @ from the iMMix ID, and add ‘PGM’ in front of them. E.g. ‘PGM12345’. You can then select the DAAN collection and enter this ID as a search term to find your resource.
Search tool
The default search facets have the same labels as in iMMix. When selecting a date field or adding a new facet, you will notice more fields in the list. Most of the fields common to iMMix and DAAN have the same labels. The biggest difference in existing fields is that ‘segment’ fields, those relating to clips within a program, now start with ‘logTrackItems.ltScenedesc’. Use the Inspect tool to see descriptions of the fields.
Inspect tool
When selecting a field for analysis, you will notice more fields in the list. Most of the fields common to iMMix and DAAN have the same labels. The biggest difference in existing fields is that ‘segment’ fields, those relating to clips within a program, now start with ‘logTrackItems.ltScenedesc’.
Advanced information about the differences in the data modelBoth the iMMix and DAAN data models have information about a program and the series and season it was part of. Unlike iMMix, DAAN does not require a program to have a season and series, so these may be omitted. Both models also have information about when the program was broadcast (publication) and when it was recorded (recording/recordinginformation).
The key differences between the DAAN and iMMix models are summarised below:
- Clips within a program, e.g. the weather forecast within a news program, were previously modelled as ‘segments’. These are now modelled as ‘scene descriptions’. At present, field names relating to scene descriptions all start with ‘logTrackItems.ltSceneDesc’.
- Timing information has been moved from carriers (now called ‘asset items’) to technical logtrack items. These fields start with ‘logTrackItems.ltTechnical’.
- Fields relating to rights have been changed a great deal. There are many fields related to IPR that start with ‘program.ipr’. Additional relevant fields are program.currentrightsholder, program.rightsdeterminationdate, program.rightslicense, program.rightslicensenote, program.rightslicenseterms
- DAAN has many new fields with enrichment information, such as face recognition, extracted labels etc. These appear with the prefix ‘logTrackItems’ at present. In due course, as these are further integrated into the Media Suite, they will be given more user-friendly labels.
Look at the "Overview iMMix DAAN metadata.csv" spreadsheet to see exactly which iMMix metadata fields correspond to which DAAN metadata fields. Many of the DAAN metadata fields beginning with ‘program’ are also available at series or season level, simply replace ‘program’ with ‘series’ or ‘season’.
Data and Resources
-
FielddescriptionsTSV
The field labels and descriptions for all fields in the collection
-
Overview iMMix DAAN metadata.csvCSV
A spreadsheet showing the NISV metadata fields in the old iMMix system and...
Additional Info
| Field | Value |
|---|---|
| Source | https://www.beeldengeluid.nl/collectie |
| Author | Mari Wigham |
| Maintainer | Mari Wigham |
| Last Updated | January 10, 2024, 11:51 (CET) |
| Created | February 12, 2020, 12:58 (CET) |
| es_index | daan-catalogue-aggr |